

藍鯨新聞4月30日訊(記者 武靜靜)趕在了五一節前,阿里巴巴開源新一代通義千問模型 Qwen3。據介紹,其參數量僅為 DeepSeek-R1 的 1/3,成本大幅下降,但性能表現不錯。
報告顯示,Qwen3-235B-A22B?在代碼、數學、通用能力等基準測試中,超過了與DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等全球頂尖模型。成為了全球最強的開源模型。
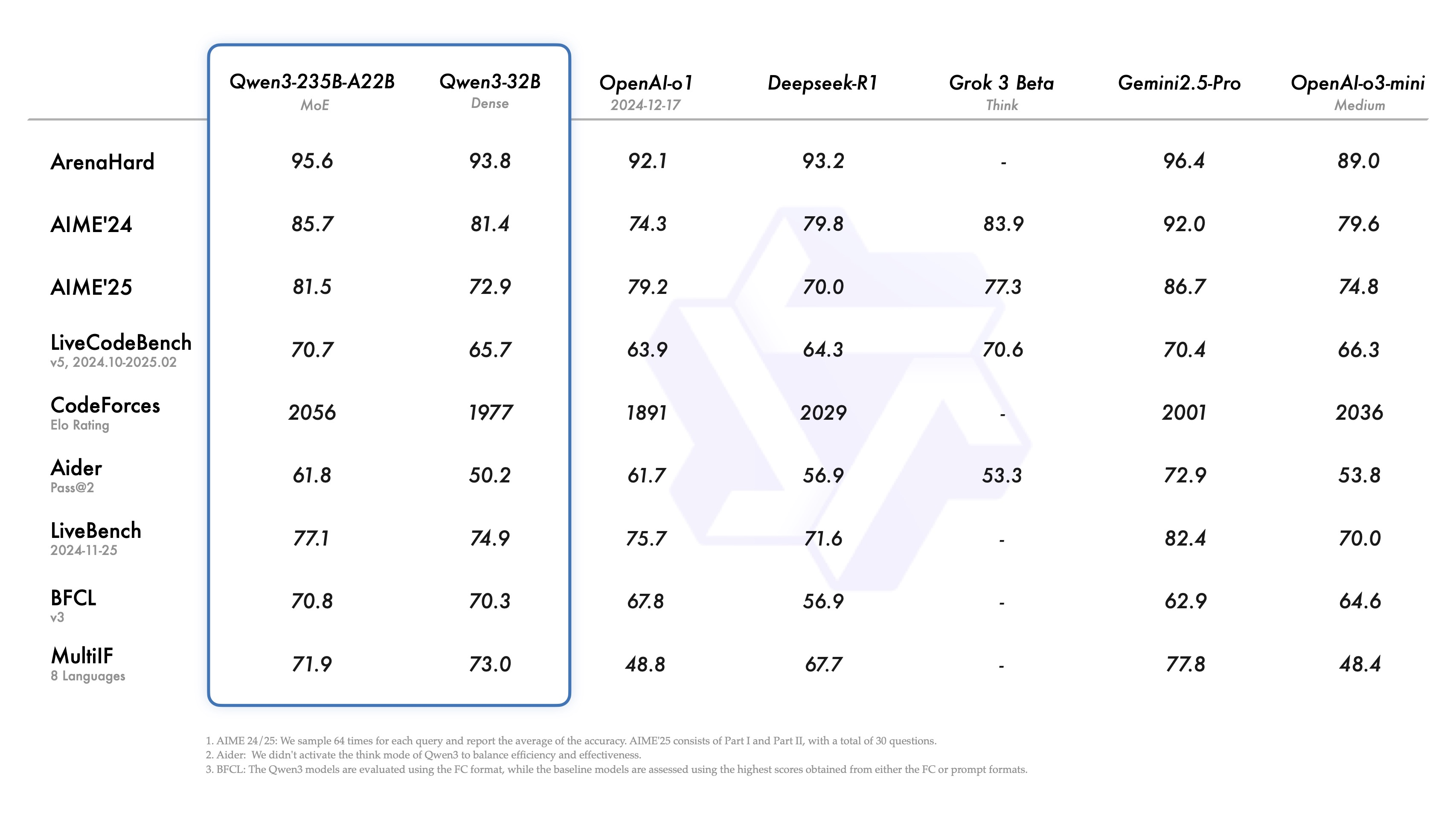
通過模型架構的改進、訓練數據的增加以及更有效的訓練方法,Qwen3實現了模型體積更小情況下,性能表現也比更大參數規模的Qwen2.5基礎模型要好。特別是在 STEM、編碼和推理等領域,Qwen3 Dense 基礎模型的表現甚至超過了更大規模的 Qwen2.5 模型。
博客中,阿里稱,Qwen3 Dense 基礎模型的整體性能與參數更多的Qwen2.5基礎模型相當。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分別與 Qwen2.5-3B/7B/14B/32B/72B-Base 表現相當。
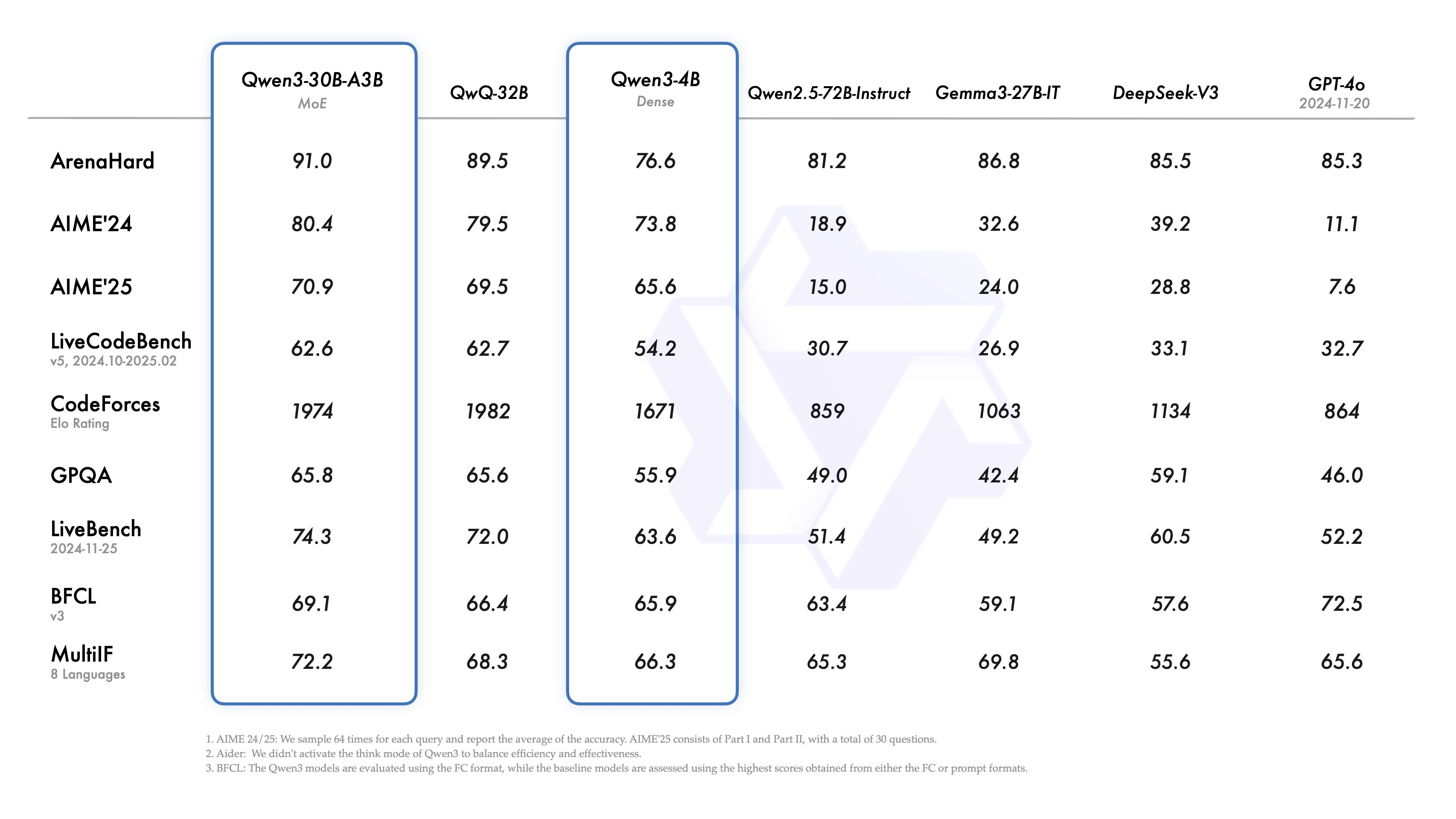
有意思的是,除了擁有235B參數的MoE模型外,Qwen 3還配備了一個小型MoE模型,即Qwen3-30B-A3B。該模型的激活參數量為3B,不及QwQ-32B模型的10%,然而其性能卻更為出色。
我們可以把MoE架構理解為一個大型的客服中心,其中有許多專門處理不同問題的專家——有的專家專門處理技術問題,有的專家處理賬單查詢,還有的專家負責解答產品使用問題。在大模型訓練過程中,當數據進入模型中后,大模型會像“客服中心”一樣,根據問題的性質被分配給最合適的專家來解決,可以提高查詢的計算效率。
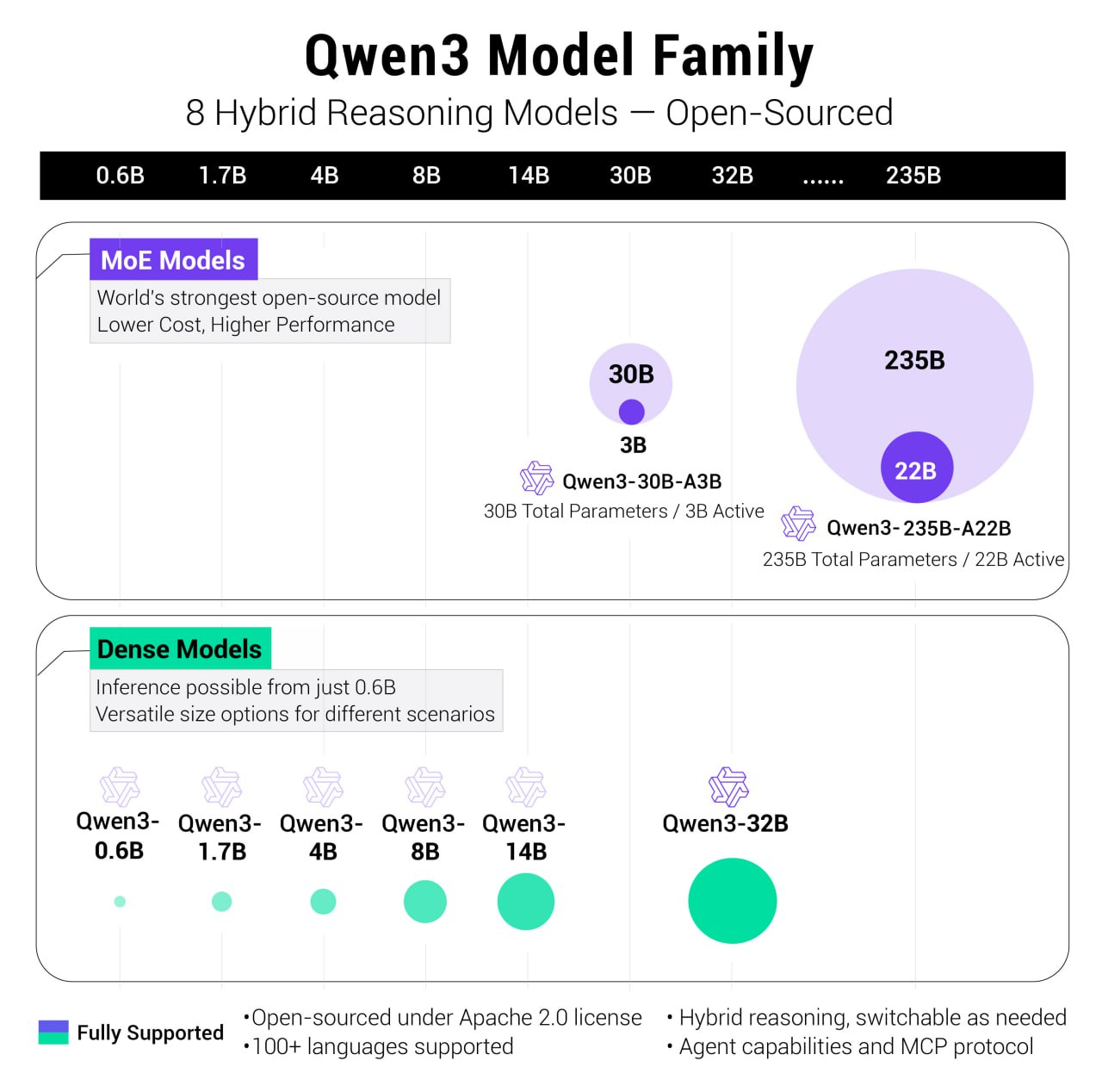
此次,阿里開的源模型有Dense模型,也有MoE模型。其中,開源了兩個 MoE 模型的權重:Qwen3-235B-A22B,一個擁有 2350 多億總參數和 220 多億激活參數的大模型,以及Qwen3-30B-A3B,一個擁有約 300 億總參數和 30 億激活參數的小型 MoE 模型。
六個 Dense 模型也已開源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B?和 Qwen3-0.6B,均在 Apache 2.0 許可下開源。可以直接商用。
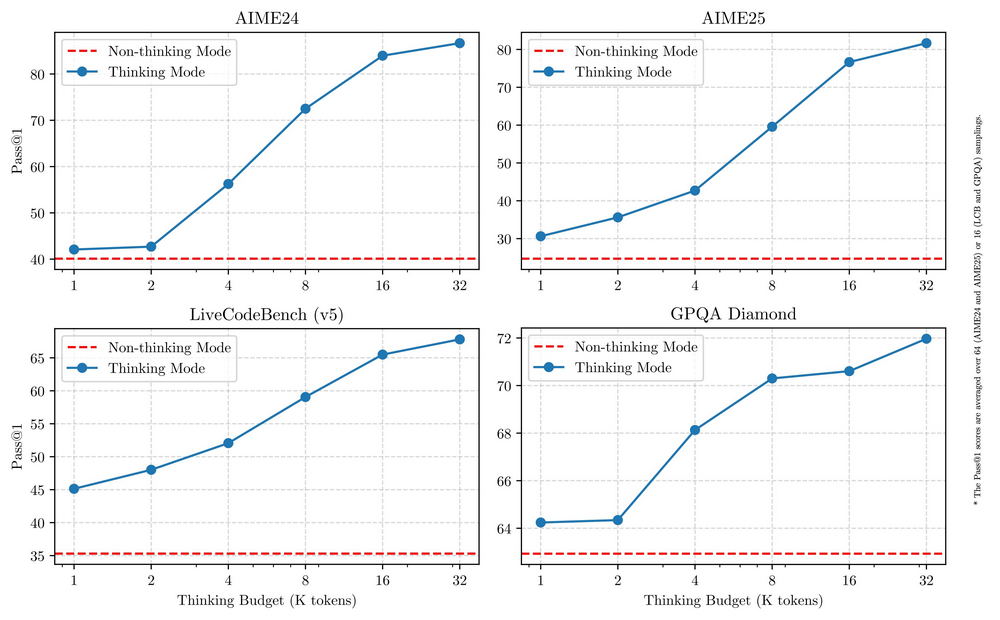
Qwen 3系列的其中一個創新點在于其"混合型"模型設計,可以在深度思考這種慢思考模式(用于復雜的邏輯推理、數學和編碼)和快思考模式(用于高效、通用的聊天) 之間的無縫切換 ,確保在各種場景下實現最佳性能。
這意味著,用戶終于不需要手動操作開啟并關閉“深度思考”功能,且擔心模型過度思考的問題了,此前,很多大模型用戶反饋稱,大模型動不動就深度思考輸出長篇大論,很多小問題也如此完全沒必要。
關鍵在于,這種快慢思考靈活切換的模式能有效的降低成本,阿里在博客中稱:這兩種模式的結合大大增強了模型實現穩定且高效的“思考預算”控制能力。這樣的設計讓用戶能夠更輕松地為不同任務配置特定的預算,在成本效益和推理質量之間實現更優的平衡。
在部署方面,阿里稱僅需4張H20即可部署千問3滿血版,顯存占用僅為性能相近模型的三分之一。這意味著相比相比滿血版deepseek R1,部署成本大降75%~65%。
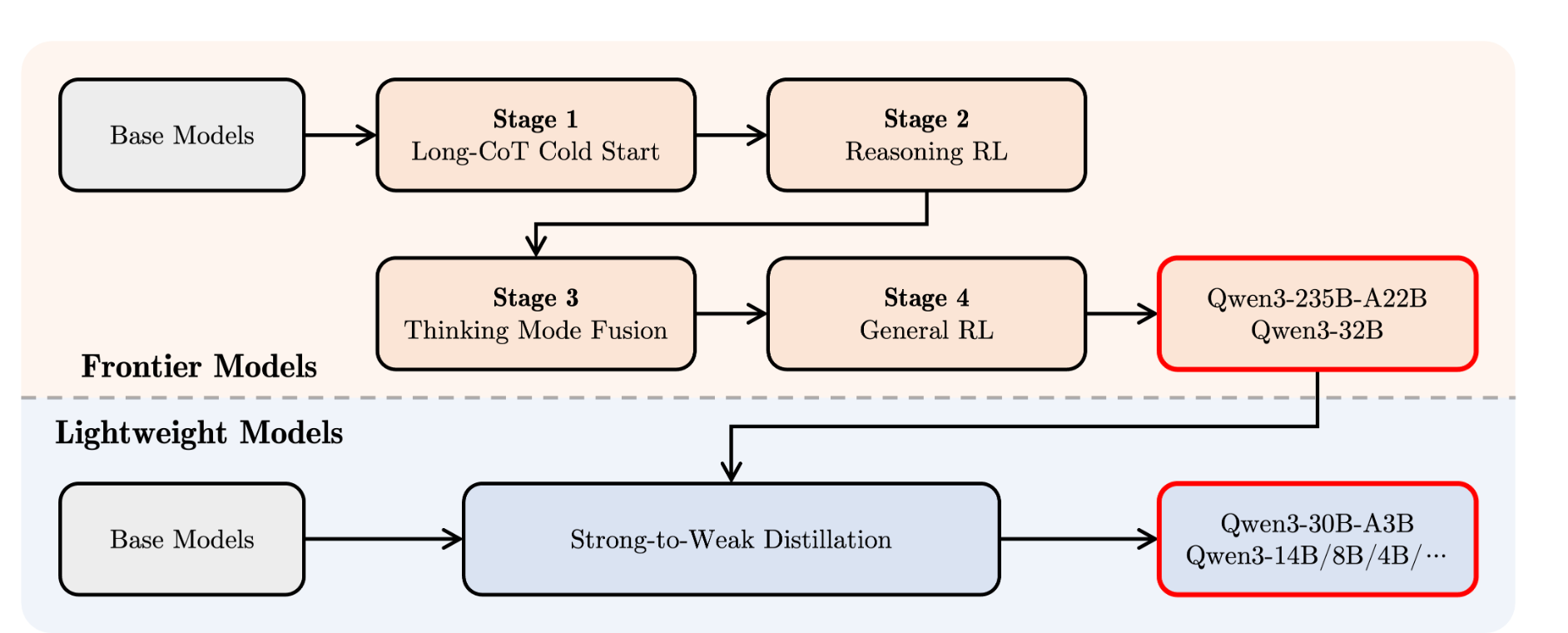
阿里介紹稱,Qwen3經過了四階段的訓練流程,相當于,先教基礎→再練深度思考→混合快慢模式→最后全面優化。阿里表示,Qwen3在工具調用、指令執行和數據格式處理方面表現優秀。建議搭配Qwen-Agent使用,它能簡化工具調用的代碼實現。
此次,阿里還專門優化了 Qwen3 模型的 Agent 和 代碼能力,同時也加強了對 MCP 的支持。在示例中看到, Qwen3 可以絲滑的調用工具。
開源正在成為阿里核心的AI戰略,從2023年起,阿里通義團隊就陸續開發了覆蓋0.5B、1.5B、3B、7B、14B、32B、72B、110B等參數的200多款「全尺寸」大模型。
在此前的一次采訪中,通義相關負責人曾告訴藍鯨新聞,“開源不是目的而是結果。只有做出真正有競爭力的產品,開源才有意義。這倒逼我們必須做到兩點:一是模型性能要達到全球SOTA水平,二是要能媲美甚至超越閉源模型。”



